Building an Enterprise Anycast CDN at the Network Edge
This series is a theory — my theory. It is not presented as a standard, a prescription, or a finished product, but as a deliberate exploration of an idea that emerges from operating large networks over time. Some parts are well‑understood practices; others are hypotheses tested through reasoning, experience, and constraint. Like any good theory, it is meant to be examined, challenged, adapted, and occasionally rejected. What follows is an attempt to think clearly and honestly about what might be possible, not to declare what must be done.
Section 2 — Anycast Is About Reachability, Not Correctness
Anycast is often described as a clever trick, or worse, as something mysterious that only large providers can safely operate. In reality, anycast is a very simple idea with very specific properties — and many of the problems people attribute to anycast come from asking it to do things it was never designed to do.
At its core, anycast answers only one question:
Which node is reachable from here, right now?
It does not answer questions about service health, application correctness, cache validity, or business intent. Those concerns must be handled elsewhere.
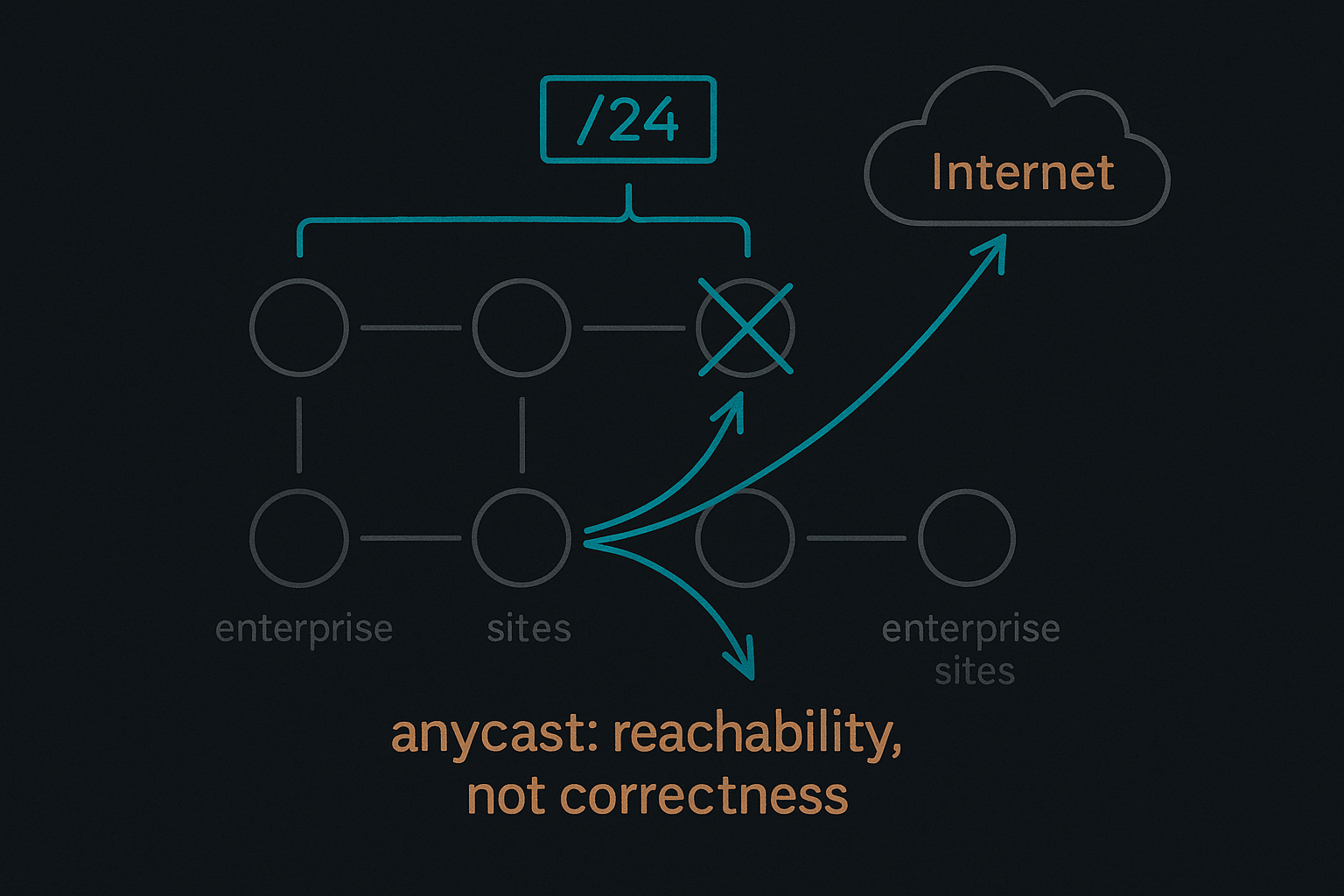
Anycast as an Ingress Primitive
In this architecture, anycast is used exclusively as an ingress mechanism.
Each edge node advertises the same public IP prefix — typically a /24 — into BGP. From the Internet's point of view, these advertisements are indistinguishable. Routing decisions are made purely on standard BGP attributes: path length, policy, and topology.
The result is straightforward:
- Clients are routed to the nearest reachable edge node
- If a node disappears, its route is withdrawn
- The Internet converges without coordination or signaling
This is a strength, not a weakness.
Anycast does not require client awareness, DNS manipulation, or application logic. It leverages the Internet's existing routing system to make a coarse but reliable decision.
The Most Common Misunderstanding
A frequent mistake is to assume that anycast should also reflect service correctness.
For example:
- "If the service is unhealthy, anycast should stop sending traffic"
- "If the cache is cold, anycast should choose another site"
- "If the backend is slow, anycast should know"
BGP cannot do these things, and attempting to force them into the routing layer usually leads to instability, excessive churn, or opaque failure modes.
In this design, anycast is deliberately constrained to a single responsibility:
Expose the edge to the Internet and withdraw it when the node itself is unavailable.
Nothing more.
Separating Reachability from Correctness
Once traffic arrives at an edge node, other mechanisms take over:
- Overlay routing determines where traffic should go next
- Service health systems advertise or withdraw service reachability
- Load balancers and caches enforce application-level behavior
By keeping anycast narrowly focused, we avoid overloading BGP with semantics it cannot safely express.
This separation is foundational. Many later design choices in this series depend on it.
Reference: Anycast in Plain Terms
For readers less familiar with anycast, the concept can be summarized simply:
- Multiple routers or edge nodes advertise the same IP address to the Internet
- Each router does this independently, from its own location
- Internet routing delivers traffic to the nearest advertisement
- If a router stops advertising, traffic automatically shifts elsewhere
That's it.
There is no magic synchronization between routers. There is no special protocol beyond BGP. There is no requirement that the routers know about each other.
Anycast is powerful precisely because it is limited.
In the next section, we will look at what happens after traffic lands on an edge node — and why a second routing domain is necessary to preserve correctness without breaking the simplicity of anycast.