Building an Enterprise Anycast CDN at the Network Edge
This series is a theory — my theory. It is not presented as a standard, a prescription, or a finished product, but as a deliberate exploration of an idea that emerges from operating large networks over time. Some parts are well‑understood practices; others are hypotheses tested through reasoning, experience, and constraint. Like any good theory, it is meant to be examined, challenged, adapted, and occasionally rejected. What follows is an attempt to think clearly and honestly about what might be possible, not to declare what must be done.
Section 3 — What Happens After Traffic Lands
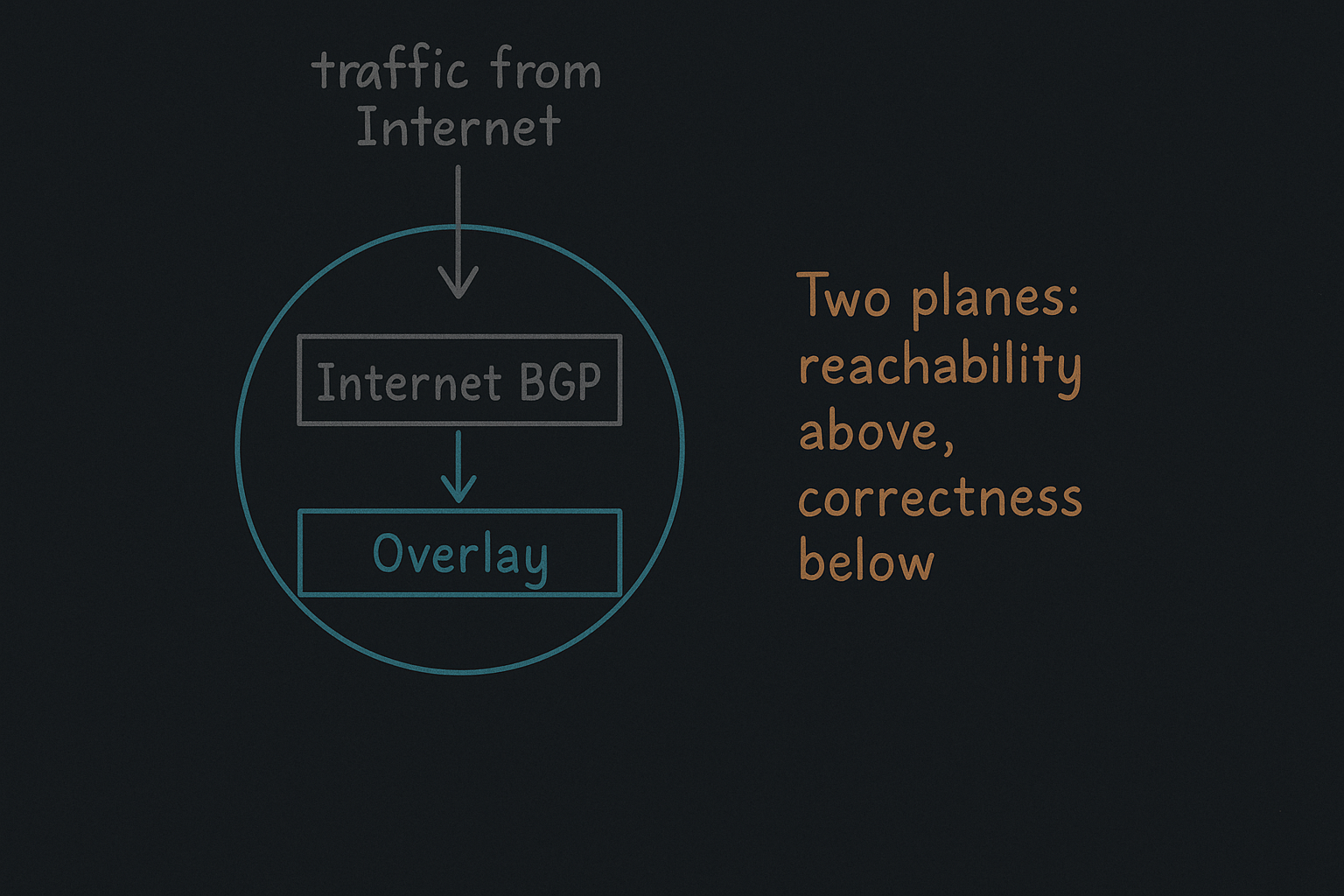
Once traffic arrives at an edge node via anycast, the most important decision has already been made: the Internet has chosen a reachable entry point. What has not yet been decided is whether that node should serve the request locally, forward it elsewhere, or decline to serve it at all.
This distinction is subtle but critical. Anycast solves reachability. It does not, and cannot, solve correctness.
Why One Routing Plane Is Not Enough
If anycast were the only routing mechanism in the system, every edge node would need to be equally capable of serving every request. In practice, this is rarely true.
Consider a few common realities:
- Not every site hosts every service
- Not every cache is warm
- Not every backend is healthy
- Some failures are partial, not total
From the Internet's perspective, these distinctions are invisible. BGP sees a prefix being advertised and assumes the node is reachable. It has no language for expressing anything more nuanced.
Trying to encode these realities directly into BGP — by rapidly advertising and withdrawing prefixes based on application state — leads to instability and hard-to-diagnose behavior.
Introducing a Second Routing Domain
To preserve the simplicity of anycast while still making correct decisions, this architecture introduces a second routing domain, separate from Internet BGP.
It is important to be explicit about what this routing domain is — and what it is not.
This is not your enterprise's internal global routing table. It is not a replacement for IGP, MPLS, or data‑center routing. It does not carry corporate subnets, user networks, or east‑west application traffic.
Instead, it is a narrowly scoped overlay routing domain whose sole purpose is to guide traffic after it has arrived at an edge node.
This internal domain exists solely to answer a different question:
Given that traffic has arrived here, where should it go next?
This routing domain:
- Is not visible to the Internet
- Does not advertise public prefixes
- Does not participate in internal enterprise routing
- Carries only tightly scoped control information
- Converges independently of Internet routing
In practice, this domain is implemented as an overlay between edge nodes.
What This Overlay Carries — and What It Does Not
The overlay routing domain is intentionally minimal.
It carries:
- Node identities (typically as /32 loopbacks)
- Service reachability signals (also as /32s)
It does not carry:
- Default routes
- Summarized networks
- Arbitrary internal prefixes
- Internet reachability
This is a deliberate constraint. By limiting what the overlay can express, we limit the damage it can do.
Correctness Through Explicit Signaling
In this model, services advertise their own availability.
If a service is healthy at a site, that site advertises reachability for that service into the overlay. If it becomes unhealthy, the advertisement is withdrawn.
Edge nodes do not infer service state. They react to explicit signals.
This has two important consequences:
- Partial failures are handled cleanly
- Incorrect inferences are avoided
Routing becomes a reflection of truth, not a guess.
Keeping the Planes Separate
The separation between Internet anycast and the internal overlay is not an implementation detail — it is the core safety property of the system.
- Internet BGP decides who gets traffic
- Overlay routing decides what happens next
Neither plane attempts to solve the other's problem.
In the next section, we will look at how this overlay is formed in the first place — including how nodes discover each other, authenticate, and establish trust without collapsing these carefully maintained boundaries.