Building an Enterprise Anycast CDN at the Network Edge
This series is a theory — my theory. It is not presented as a standard, a prescription, or a finished product, but as a deliberate exploration of an idea that emerges from operating large networks over time. Some parts are well‑understood practices; others are hypotheses tested through reasoning, experience, and constraint. Like any good theory, it is meant to be examined, challenged, adapted, and occasionally rejected. What follows is an attempt to think clearly and honestly about what might be possible, not to declare what must be done.
Section 7 — Hard Safety Boundaries
Up to this point, the architecture has relied on careful separation of concerns: ingress versus correctness, discovery versus trust, Internet versus private transport. These separations reduce complexity, but they do not eliminate the possibility of mistakes.
People make errors. Automation has bugs. Systems evolve.
The final question, then, is not whether mistakes will happen — but how far they can propagate when they do.
The Value of Absolute Limits
One of the most effective safety mechanisms in large networks is also one of the simplest: hard limits enforced by routing policy.
Rather than attempting to validate every possible behavior, the system defines a small, explicit set of outcomes that are allowed — and rejects everything else.
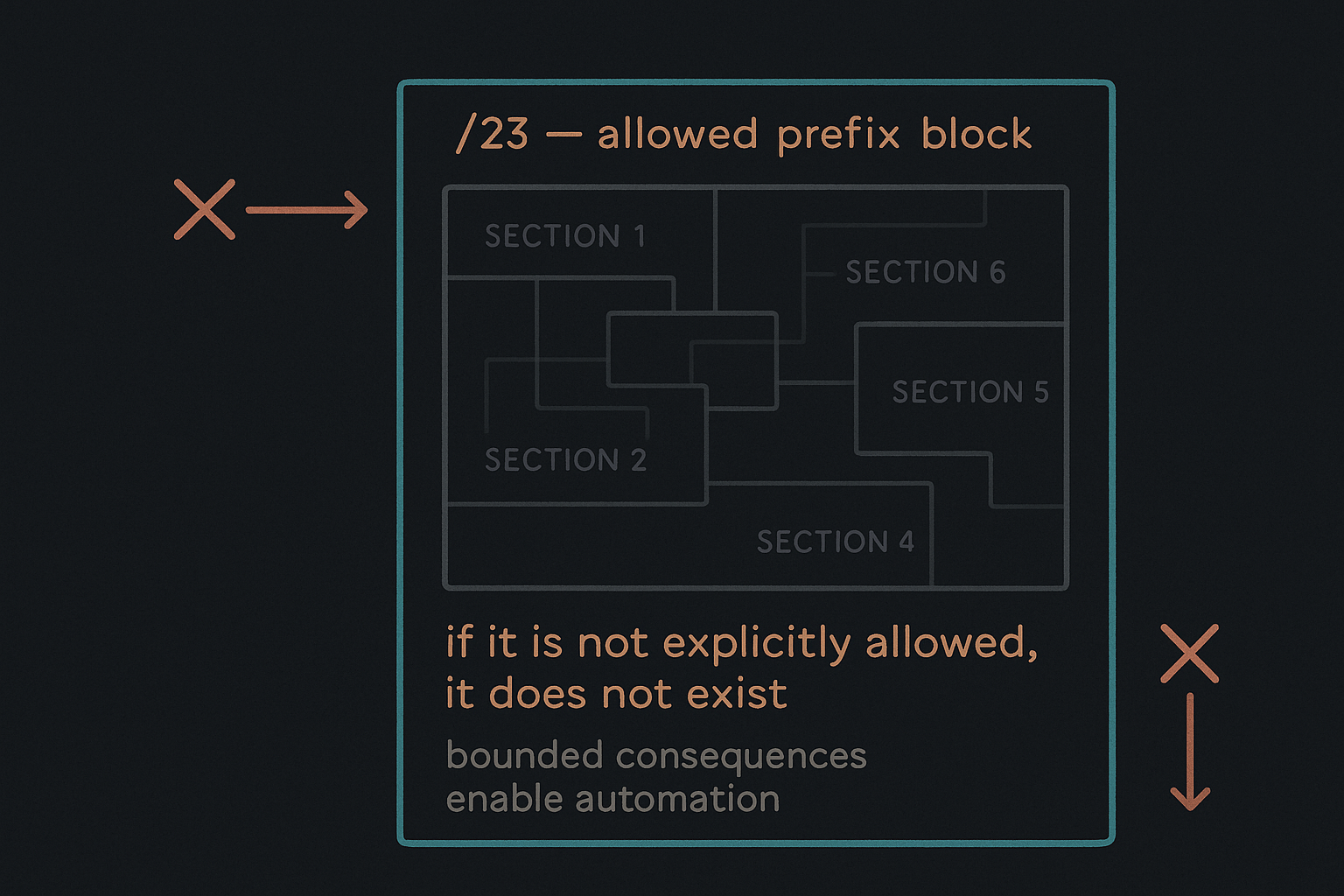
In this architecture, that limit takes the form of a tightly scoped prefix block.
A Single Place Where Routes Are Allowed to Exist
All node identities and service identities live inside a single, well-defined address block — for example, a /23 reserved exclusively for this system.
Within this block:
- Each edge node has a unique /32
- Each service identity is represented as a /32
Outside this block, no routes are ever accepted.
This rule is enforced at the boundary where overlay routing information is consumed.
What This Prevents
This single constraint eliminates an entire class of failures:
- Accidental default routes
- Route leaks from internal networks
- Misconfigured summaries
- Malicious or compromised peers advertising arbitrary prefixes
Even if a node behaves incorrectly, it cannot escape the sandbox defined by policy.
Safety That Enables Automation
Because the allowed outcome space is so tightly constrained, higher-level automation becomes safer.
- New nodes can be introduced gradually
- Peering can be established automatically
- Service advertisements can change dynamically
If something goes wrong, the blast radius is mechanically limited.
This is what makes automation viable in a distributed system: not perfect code, but bounded consequences.
Defense in Depth, Not Cleverness
This policy is intentionally blunt.
It does not attempt to understand intent. It does not attempt to infer correctness. It simply enforces the rule:
If it is not explicitly allowed, it does not exist.
When combined with the earlier layers — authentication, adjacency control, overlay scoping — this creates a system that fails closed rather than failing unpredictably.
A System That Can Be Operated
At scale, operability matters more than elegance.
Hard safety boundaries ensure that:
- Engineers can reason about failure
- Changes can be rolled out incrementally
- Recovery paths are exercised regularly
The system remains understandable, even when parts of it are under stress.
In the final section of this series, we will step back and look at the architecture as a whole — not to summarize it, but to reflect on what kinds of organizations it fits, and what tradeoffs it deliberately accepts.